De los sistemas expertos a la inteligencia artificial
La Inteligencia Artificial (IA) es una tecnología con más de siete décadas de historia. Durante este periodo hemos pasado de sistemas de reglas rígidas a modelos que interpretan contexto y generan texto, imágenes y código. Esta tecnología puede ser definida como la capacidad de una máquina de aprender patrones y hacer predicciones, que a diferencia de sistemas binarios (sí/no), trabaja con probabilidades lo que le permite adaptarse a distintos contextos.
Para comprender mejor su alcance, conviene distinguir tres tipos de "inteligencia": humana (sin intervención de máquinas), artificial (máquina que opera sin intervención humana directa, completando tareas repetitivas) y aumentada (colaboración humano-máquina). Esta última combina lo mejor de ambos: creatividad y emocionalidad humana que otorgan criterios a las decisiones con la precisión y repetibilidad de las máquinas obtenida a partir de los datos con que se alimentan.
Remontándonos a sus orígenes es necesario reconocer las eras de los datos. La primera era corresponde a la tabulación, la que abarca desde los primeros intentos de clasificar información, como el ábaco de los recaudadores chinos hace más de dos mil años hasta el auge de las máquinas tabuladoras de IBM a inicios del siglo XX. Su característica central fue "trocear" y organizar datos, para revelar patrones útiles en censos, cálculos científicos y estadísticas, principalmente a partir de datos estructurados.
Luego llegó la era de la programación, a partir de la Segunda Guerra Mundial, cuando surgieron los primeros ordenadores electrónicos programables como el ENIAC. A través de esos equipos, que podían ejecutar más de un tipo de instrucción (lo equivalente a los programas actuales), se buscaba acceder a una mayor cantidad de "datos oscuros". Estos equipos eran capaces de resolver cálculos complejos, desde trayectorias de artillería hasta misiones espaciales. Sin embargo, el problema del exceso de datos creció tanto que ni las computadoras más potentes podían procesarlos a tiempo, marcando un límite a este modelo de trabajo.
Hoy en día estamos en la era de la IA, inaugurada en 1956, la cual abrió un nuevo horizonte: las máquinas ya no solo siguen instrucciones, sino que aprenden patrones y hacen predicciones a partir de datos masivos (incluyendo aquellos no estructurados), logrando en los últimos años alimentarse de la totalidad de los datos oscuros. Esta etapa transformó el manejo de la información, incorporando algoritmos capaces de procesar lo no estructurado, encontrar correlaciones ocultas y asistir en la toma de decisiones humanas. Desde entonces, la inteligencia artificial se ha convertido en el eje de un manejo de datos más profundo, flexible y predictivo.
Dentro de la historia de la inteligencia artificial podemos segmentar tres grandes periodos marcados por avances y retrocesos. El primer periodo comienza en 1956, iniciado con el acuñamiento del término de Inteligencia Artificial en la conferencia de Dartmouth. Esta fue una etapa de entusiasmo en la que se lograron progresos notables: máquinas capaces de resolver problemas matemáticos, demostrar teoremas y procesar lenguaje sencillo. Sin embargo, hacia los años setenta se evidenciaron limitaciones técnicas y conceptuales, lo que llevó al primer invierno de la IA, con un brusco descenso en el financiamiento y el interés.
El segundo periodo corresponde a la década de 1980, en el cual los sistemas expertos devolvieron el optimismo. Estos sistemas permitían la aplicación de conocimientos específicos mediante reglas lógicas, invirtiéndose grandes recursos en su desarrollo. No obstante, su alcance resultó insuficiente y la irrupción de los ordenadores personales desplazó el interés hacia otras áreas. Esto dio paso al segundo invierno de la IA, en el cual muchas empresas del sector quebraron y la investigación volvió a enfriarse.
El tercer periodo se inicia a mediados de los años noventa, cuando la potencia de cómputo alcanzó niveles capaces de sostener verdaderos avances. Surgieron hitos emblemáticos: Deep Blue vence al campeón mundial de ajedrez (1997), un vehículo autónomo de Stanford atraviesa el desierto (2005), y Watson de IBM supera a los humanos en Jeopardy! (2011). Desde entonces, la IA se ha consolidado como una disciplina madura, con aplicaciones en ciencia, salud, industria y vida cotidiana.
Este crecimiento no ha parado, definiéndose niveles de desarrollo para la aplicación de la IA actual. El primero de ellos fue la IA estrecha (2010-2015), el cual agrupa sistemas para tareas muy acotadas principalmente a nivel de investigación. Actualmente, nos encontramos en el nivel de IA amplia que corresponde a soluciones empresariales integradas a procesos y productos. Y a futuro (2050), se espera que llegue el nivel de IA general con una capacidad de rendimiento comparable al humano de forma amplia. Cabe destacar que estos niveles no son mutuamente excluyentes. Hoy convivimos con aplicaciones de IA estrecha y amplia para dar solución a diferentes problemas, mientras que la IA general sigue siendo una expectativa de largo plazo.
Un poco de historia
La IA ha presentado muchos avances y a continuación se detallan algunos de ellos junto a conceptos claves.
Línea de tiempo por décadas
- 1940-1950: bases teóricas (Máquinas de Turing, cibernética). 1950: Prueba de Turing.
- 1956: Conferencia de Dartmouth: nace el término "IA".
- 1960s: ELIZA, redes semánticas, juegos (damas, ajedrez).
- 1970s: SHRDLU, lógica y mundos de bloques; primer invierno de la IA.
- 1980s: auge de sistemas expertos y redes neuronales (Hopfield, backpropagation); segundo invierno al final de la década.
- 1990s: ML "clásico": SVM, árboles, Naive Bayes, HMM; 1997: Deep Blue vence a Kasparov.
- 2000s: Random Forest, boosting (AdaBoost/GBM); visión y voz mejoran con datos y cómputo.
- 2010s: Deep Learning (CNN, RNN/LSTM); 2016: AlphaGo; 2017: Transformers.
- 2020s: IA generativa (LLM, difusión), copilotos y agentes.
De sistemas expertos a aprendizaje a partir de datos
Los primeros sistemas comerciales enfocados en automatización de decisiones fueron los sistemas expertos (1960-1980). Estos capturaban el conocimiento en reglas IF-ELSE (SI-ENTONCES) bajo la misma lógica que la programación de computadores que conocemos. Funcionaban bien en dominios acotados, como diagnósticos médicos básicos o configuración de equipos, pero eran costosos de construir y mantener (especialmente en relación a las bases de conocimiento), y difíciles de extender a las múltiples excepciones del mundo real. Por ello, con el tiempo el foco se desplazó a que las máquinas aprendan directamente de los datos.
Esta necesidad de aprendizaje automático dio origen al Machine Learning (ML). Su base son los algoritmos, un conjunto de operaciones que recibe datos, los procesa y entrega un resultado, permitiendo reconocer patrones (ejemplo: relacionar luz solar y temperatura del agua para predecir el clima). Cuando varios algoritmos se entrenan y se ajustan para mejorar su precisión, forman un modelo. A diferencia del software convencional, un modelo puede autoprogramarse: reanaliza datos y corrige sus parámetros (como pesos o sesgos) para mejorar con el tiempo. El ML "clásico" usa algoritmos relativamente sencillos, ideales para datos estructurados y decisiones interpretables.
Para conseguir esta autoprogramación existen 3 modalidades de aprendizaje: supervisado (aprende con ejemplos etiquetados), no supervisado (descubre una estructura a partir de una pregunta y un gran conjunto de datos, detectando patrones sin etiquetas) y por refuerzo (mejora por ensayo y error, mediante "recompensas"). Estos sistemas se expresan a través de árboles de decisión o regresiones lineales/logísticas para permitir el análisis de los datos.
Entre los algoritmos más representativos del aprendizaje clásico se encuentran:
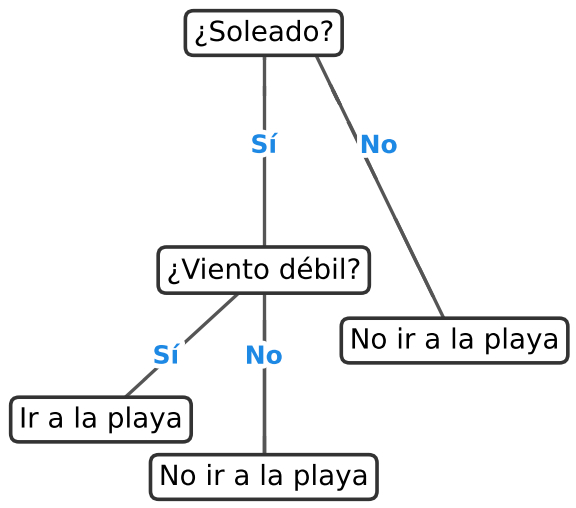
- Árbol de decisión: funciona como un diagrama de flujo invertido, con un nodo raíz que se ramifica en nodos internos y termina en hojas que representan las decisiones finales. Se entrena con datos conocidos y luego permite tomar decisiones basadas en reglas aprendidas. Por ejemplo, decidir si conviene ir a la playa según la predicción del tiempo atmosférico, oleaje y fecha.
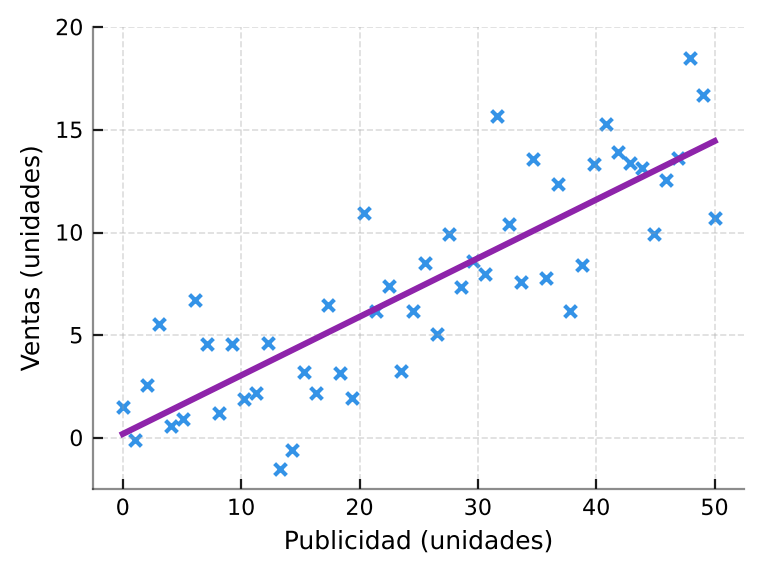
- Regresión lineal: representa la relación entre variables como una línea recta que resume una serie de puntos con cierto nivel de dispersión. Permite responder preguntas como: "Si invierto más en publicidad, ¿cuánto subirán las ventas?". El modelo matemático busca trazar la línea que mejor aproxima los datos reales para hacer predicciones simples pero útiles.
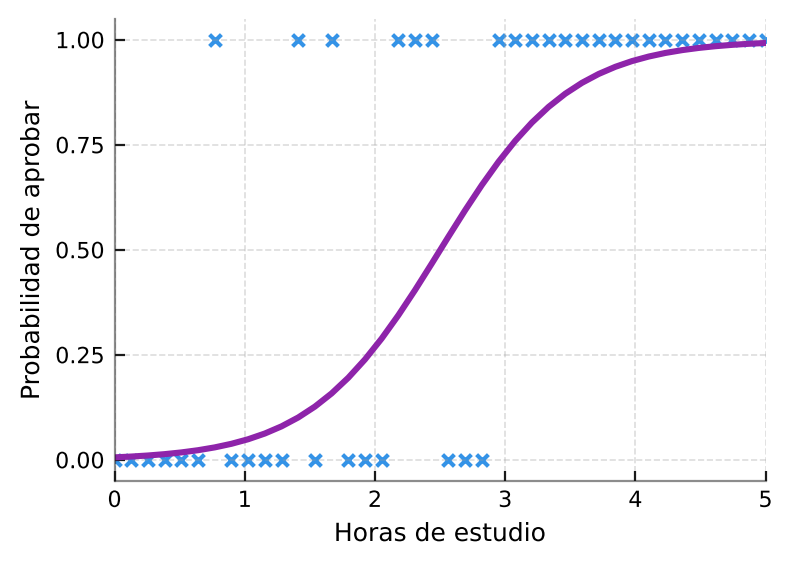
- Regresión logística: en situaciones donde el resultado es una probabilidad entre 0 y 1, se utiliza una curva en forma de S, llamada función sigmoidea. Sirve para responder preguntas como: "Con X horas de estudio, ¿cuál es la probabilidad de aprobar un examen?". A diferencia de la regresión lineal, aquí no se busca un valor exacto, sino una probabilidad de entre dos alternativas (Siguiendo el ejemplo, Aprobado/Reprobado).
La comprensión del modelo matemático puede resultar algo compleja, pero se podría resumir así: La regresión lineal estima cuánto cambia Y cuando cambia X, mientras que la regresión logística estima la probabilidad de que ocurra Y cuando cambia X.
En un nivel más avanzado del aprendizaje clásico destacan técnicas como el Random Forest, muy utilizado para clasificar y segmentar datos tabulares, y las máquinas de soporte vectorial (SVM), aplicadas con éxito en texto e imágenes antes de la era del aprendizaje profundo. Estos modelos marcaron un paso intermedio importante hacia la sofisticación actual, ofreciendo predicciones robustas y aplicables en múltiples industrias.
Cabe destacar que, aunque el aprendizaje profundo ha tomado protagonismo, el aprendizaje automático clásico no está obsoleto. Sigue siendo valioso por su menor coste de implementación y sus resultados son más fáciles de interpretar por humanos, lo que lo mantiene útil para el análisis de datos especialmente en entornos empresariales.
A modo de ejemplo, la regresión logística ayuda en marketing a predecir la probabilidad de compra de un cliente, mientras que un árbol de decisión puede guiar a una empresa para decidir cuándo realizar un reabastecimiento y evitar quiebres de stock.
Ciencia de datos
Con el auge de más datos y nuevas herramientas, el aprendizaje clásico se integró en un campo más amplio: la ciencia de datos. Este nuevo campo de trabajo ha potenciado la estadística clásica al aplicarla en un entorno de abundantes datos y disponibilidad de múltiples herramientas. Esta forma de trabajo se basa en formular preguntas, explorar, modelar y comunicar resultados para facilitar la toma de decisiones. En este mundo aparecen herramientas de trabajo como:
- Python:
pandas,scikit-learn,matplotlib,TensorFlow/PyTorch. - R: análisis y visualización (
ggplot2) con gran ecosistema en estadística aplicada.
Mediante estas herramientas se ha facilitado el acceso, tanto a empresas como centros académicos, para experimentar y crear valor con datos.
Como es sabido, la informática reduce el mundo a datos. Y para procesarlo con la técnica más apropiada, se suele hablar de tres categorías de datos:
- Estructurados: son datos cuantitativos y están bien organizados (son tabulables), como por ejemplo una hoja de cálculo de datos (Excel).
- No estructurados: son datos cualitativos sin forma fija (sin estructura), aquí nos encontramos con texto libre, imágenes, audios, historiales médicos, etc. Su valor es cada vez mayor para las empresas ya que permiten la generación de nuevos productos o perfilamiento de usuarios.
- Semiestructurados: Corresponde a la combinación de datos no estructurados con características de datos estructurados a través del uso de metadatos. Por ejemplo, mediante etiquetas EXIF, ID3, JSON o XML, que se usan para categorizar imágenes o audios u otros contenidos facilitando su indexación.
Como podemos suponer, gran parte de la data del mundo corresponde a no estructurada. Para poder extraer valor de texto, imagen y audio se requiere un enfoque más ambicioso: el aprendizaje profundo.
Del ML clásico al aprendizaje profundo
La última revolución en aprendizaje automático fueron las redes neuronales, sistemas inspirados en el cerebro, que trabajan realizando tareas específicas con un estímulo que genera un resultado mediante cálculo puro y avanzado. Gracias a la existencia masiva de datos (internet, sensores y digitalización de registros), GPUs con alta capacidad de procesamiento y nuevas técnicas de entrenamiento, es que surgió el aprendizaje profundo. Algunas de las técnicas más relevantes son:
- Redes neuronales convolucionales (CNN): visión por computadora (clasificación, detección, segmentación), lo que permite analizar radiografías o indicar al médico qué zonas de un escáner revisar con mayor detalle.
- Redes neuronales recurrentes (RNN)/ y sus variantes LSTM/GRU: texto y voz secuenciales (traducción, ASR), que se puede utilizar por ejemplo para procesamiento de voz facilitando la transcripción de llamadas o detección de emociones en una atención al cliente.
- Atención y Transformers (2017): paralelismo, contextos largos; base de los LLM.
El gran salto en los últimos años lo dieron los Transformers, una arquitectura que revolucionó el procesamiento de texto, imágenes y otros datos secuenciales. A diferencia de los modelos anteriores que procesaban la información de manera secuencial (como las RNN), los Transformers utilizan un mecanismo de atención que permite considerar en paralelo todas las partes relevantes de una secuencia. Esto los hace mucho más rápidos y capaces de manejar contextos largos, sentando las bases de los actuales modelos de lenguaje a gran escala (LLM) como los que usamos hoy en asistentes y copilotos de IA.
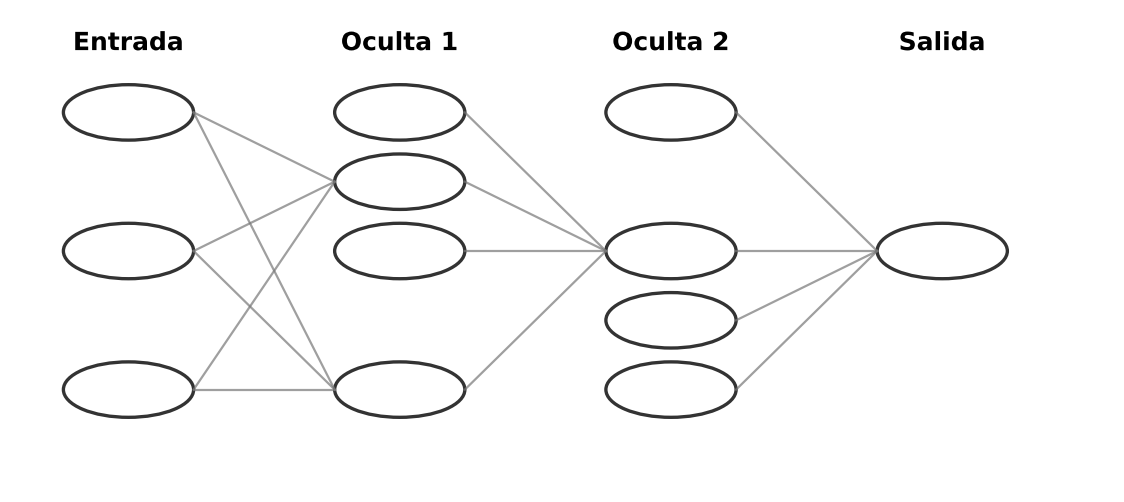
En el corazón de las redes neuronales modernas se encuentra el perceptrón, una unidad matemática inspirada en la neurona biológica (axones, dendritas y terminales). Cada perceptrón recibe varias entradas (datos), les asigna un peso y produce una salida según una función de activación. Esa función (por ejemplo, una sigmoide) decide si el nodo "se activa" o no al superar cierto umbral. Al conectar muchos perceptrones en capas (entrada → capas ocultas → salida), el sistema aprende relaciones cada vez más complejas. Es importante recalcar que este sistema no piensa, calcula. Cuando estos grupos de perceptrones se organizan en múltiples capas, hablamos de aprendizaje profundo, capaz de capturar desde patrones simples hasta representaciones abstractas.
En una red neuronal, los datos entran, pasan por capas de nodos que aplican funciones y pesos, y salen como una predicción o recomendación. Una manera simple de visualizar cómo aprende es pensar en el ensayo y error. La red hace una conjetura inicial, compara su resultado con ejemplos conocidos y ajusta parámetros para acercarse a la respuesta correcta. Es como subir una colina con los ojos vendados: avanzas, "sientes" si subiste o bajaste, corriges el rumbo y repites hasta aproximarte a la cima.
Este proceso iterativo permite que el modelo emita respuestas junto con un valor de confianza (qué tan seguro está). Por ejemplo, ante varias opciones de tratamiento médico, el sistema puede sugerir alternativas y su confianza relativa, pero la decisión final sigue siendo humana.
Cuando un solo perceptrón o pocas capas no bastan para problemas complejos (especialmente con datos no estructurados como texto, imagen o audio), se recurre a redes neuronales profundas (DNN), con muchas capas organizadas en bloques. Esa profundidad hace posible resolver tareas difíciles en tiempos razonables y está en la base de aplicaciones modernas de visión, lenguaje y recomendaciones.
IA generativa
Gracias a los avances presentados por el aprendizaje profundo, se estableció la posibilidad de generar contenido original dando origen a la IA generativa. Ya no solo es capaz de clasificar o predecir datos, sino que crea contenido nuevo. Mientras que los modelos tradicionales (discriminativos) se enfocan en distinguir (por ejemplo, si una imagen corresponde a una bicicleta o a un camión), los modelos generativos pueden producir una imagen completamente nueva que se asemeje a una bicicleta nunca antes vista. Esta capacidad de inventar contenido original ha despertado gran interés porque abre la puerta a imágenes, textos, música, videos o incluso datos sintéticos creados de cero.
El impacto de esta tecnología ha sido comparado con la invención de la electricidad o el automóvil: está cambiando la forma en que trabajamos, aprendemos y creamos. Lo que la hace tan poderosa es su velocidad, la calidad de sus resultados y la facilidad de uso: basta con dar una instrucción en lenguaje natural (un prompt) para que genere algo nuevo en segundos.
¿Cómo funciona? Una persona entrega a la IA una gran cantidad de datos (imágenes, sonidos, textos, números). La red neuronal analiza estos datos, descubre patrones y relaciones y luego, a partir de ese conocimiento, es capaz de producir algo original que conserva las características aprendidas. Así, si la entrenamos con miles de fotos de perros, podrá inventar una raza nunca que nunca ha existido, pero que parece real. También puede redactar una historia o componer música siguiendo las reglas y estilos que aprendió durante el entrenamiento.
Existen tres grandes familias de modelos generativos que ayudan a entender esta tecnología:
- Codificador automático variable (VAE): funciona como un artista que observa una pintura, hace un boceto simplificado y luego crea una nueva obra a partir de ese boceto. El sistema comprime la información y luego la reconstruye, capturando la esencia para generar variantes.
- Red generativa antagónica (GAN): se puede explicar como un duelo entre un falsificador y un crítico de arte. El falsificador dibuja cuadros falsos y el crítico intenta detectar cuáles son reales y cuáles no. En este juego de mejora constante, el falsificador termina produciendo obras casi indistinguibles de las originales.
- Modelos autorregresivos: es como un narrador que escucha el inicio de una historia y la continúa palabra por palabra, prediciendo lo que sigue en función de lo anterior. De este modo, genera un texto coherente (e incluso código, permitiendo a cualquiera construir aplicaciones a partir de una idea).
En la práctica, los modelos autorregresivos se aplican en los llamados Large Language Models (LLM), que aprenden de enormes colecciones de textos y luego escriben respuestas, redactan documentos o traducen. Usan técnicas como el preentrenamiento auto-supervisado, el ajuste fino, o el aprendizaje por refuerzo con retroalimentación humana (RLHF) para alinear sus respuestas con lo que las personas consideran útil y adecuado. Y todos los modelos anteriores se entremezclan generando interfaces en las que uno realiza una solicitud, es dirigida al modelo correspondiente y se obtiene un resultado.
En resumen, la IA generativa representa una evolución del aprendizaje automático clásico hacia un terreno mucho más creativo y amigable. Gracias a las redes neuronales profundas, hoy tenemos máquinas que aprenden de patrones y producen resultados que antes parecían exclusivos de la imaginación humana. Aunque la IA todavía comete errores o genera resultados inesperados, cada avance nos acerca a aplicaciones más sorprendentes y prácticas. Por ejemplo, un LLM puede mantener conversaciones amenas en centros de apoyo, resolver problemas y reducir ansiedad, mientras que los modelos de imagen ayudan a generar bosquejos que aceleran la productividad en el diseño de productos.
Pero la IA generativa no está exenta de errores, puede alucinar (dar respuestas inventadas). Para subsanar esto se cuenta con técnicas como grounding mediante Retrieval-Augmented Generation (RAG), verificación cruzada de resultados y solicitud de citación obligatoria, además de la revisión humana por expertos. También se debe evitar el sobreajuste (overfitting) que es cuando el modelo "memoriza" el entrenamiento sin aprender patrones útiles, lo que se traduce en errores al tener que interpretar datos desconocidos.
Pasando a lo práctico, ¿qué hay que saber para trabajar con IA?
Como hemos podido ver, la IA no es magia. Es ingeniería, datos y decisiones humanas. Mientras algunos problemas seguirán resolviéndose mejor con modelos clásicos, otros exigirán aplicaciones más avanzadas en conjunto con evaluación humana. Entendiendo su historia y límites, podemos aprovecharla como una aliada para pensar, crear y servir mejor a las personas. Este aumento de productividad nos abre las puertas a nuevas oportunidades tanto en la vida personal como en el mundo laboral y académico.
Para poder hacer un uso efectivo de la IA, a nivel de ingeniería informática, se requiere una combinación de bases matemáticas, herramientas técnicas y habilidades. Algunos de los conocimientos sugeridos son:
- Matemáticas aplicadas: álgebra lineal (vectores, matrices), probabilidad y estadística (descriptiva e inferencial), y nociones de procesamiento de señales.
- Lenguajes informáticos: Python (ecosistema de IA/DS), R (estadística aplicada), SQL (bases de datos relacionales), conocimiento en redacción de prompts.
- Bibliotecas y frameworks: NumPy (cálculo numérico), SciPy (ciencia e ingeniería), scikit-learn (ML clásico), TensorFlow y PyTorch (deep learning).
- Visualización y BI: Tableau y Microsoft Power BI para generación de dashboards.
- Ética: reconocer sesgos, el valor de la privacidad y las políticas de uso responsable. Ser criterioso con riesgos sistémicos como la desinformación, la dependencia excesiva o la concentración de poder en pocos proveedores.
Las habilidades más relevantes son poder trabajar en proyectos con equipos multidisciplinarios y poder explicar resultados a audiencias no técnicas. Para hacer un correcto uso de LLM, se requiere pensamiento crítico y analítico que permita formular buenas preguntas y evaluar evidencia y respuestas. Esto aparte del Aprendizaje continuo que se basa en la curiosidad, flexibilidad y actualización permanente para un entorno de conocimiento y herramientas cambiante.
Dado que la aplicación de la IA depende del campo de trabajo, es recomendable contar con conocimiento específico del área (salud, finanzas, sector público, etc.). La combinación de bases técnicas + habilidades blandas + contexto del sector es lo que habilita la adopción de IA con impacto real. Así, lo que comenzó como sistemas de reglas rígidas hoy exige profesionales capaces de comprender tanto la técnica como el contexto humano en el que se aplica.